Machine Learning from a Bayesian perspective
Artificial Intelligence, machine learning, and data science. All buzzwords that have seen a surge in popularity admits the turn of the 21st century. With recent advancement in big data analytics and computational power, our current understanding of how data can shape our lives have changed. From social media trends, fake news, to changes in laws concerning data privacy, it is clear that our world is changing, and at the centre of all this hype: machine learning.
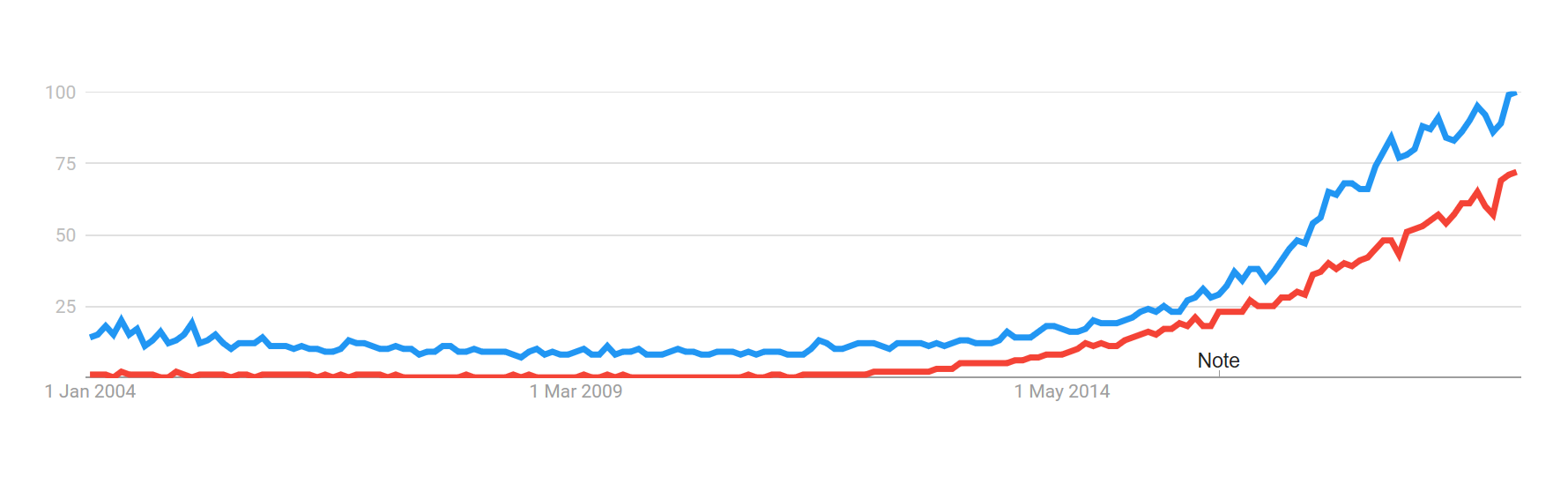
Google search trends on machine learning (blue) and data science (red) over the past 15 years.
But what is machine learning? To put it simply machine learning is a subset of the field of artificial intelligence (AI). It refers to the notion of being able to infer something new from recognising patterns in data. It is the idea that we can teach systems of machines the ability to automatically learn and make meaningful decisions based on said data; without being explicitly programmed. But at the end of the day, it’s all just probabilities and statistics … but also slightly more. To understand what machine learning is truly capable of, as apposed to frequentist statistics, we need to take a step back from the rigid mathematical framework that defines the algorithms, and look at the philosophical intuition behind machine learning first. To start let us ask ourselves, what is learning? How do we humans learn? And can we mimic the learning process to teach machines to do the same? If so, this may enables us to build smarter systems and computers.
The philosophy
I believe that the basis of learning itself comes from observing new information. As one see something new, we can infer about something new as well. This is no different than how data becomes the central focus of machine learning. There are 2 common facets in machine learning: supervised learning vs. unsupervised Learning. To give an analogy based on how we humans learn, think of supervised learning as learning from guidance. Similar to how our parents have guided us as we grow, they helped us determine what is right or wrong, and what is useful or not. We have come to learn what holds meaning in our lives through the ‘labels’ taught by our parents. On the other hand, unsupervised learning is like perceiving the world through our own eyes, making decisions and inference based on how we personally interpret the information around us.
With that being said, humans -in away- are like machines too. Our personalities define who we are and yet they are subject to change, dependent on our environment and upbringing. We are programmed, be it from nature, nurture or even both. But of course, there is so much more than that to what makes one human. A whole series of unanswerable existential questions make up what it truly means to be human. Such complex ideas like emotions, consciousness, and free-will are to hard to quantify, and much less capable of being boiled down to statistics. But we don’t need to model the entire human brain to create an AI. All we seek is to build smarter computers that can understand the semantics in the data they process … to a certain extent. After all, the whole point of modelling something is to do away with all that is unnecessary or hard to grasp, and simply focus on the easy stuff.
“All models are wrong, but some are useful.”
– George Box
A model is a simplified framework of the real-world, with layers of abstraction to only account for the relevant; enabling us to limit the uncertainty around. Much as how humans learn, machines learn the same way. We make assumptions and build models of how the world works based on our beliefs of how it should be, but as we see new information our beliefs can change; adjusting our perspective - such is the process of learning.
Many of us were introduced to the concept of probabilities from a ‘frequentist’ perspective, i.e. we viewed probabilities as mere frequencies of events for random variables. However, this is too limited for machine learning purposes, as we want to make inference over things that we have not observe yet, and so we must now view things from the Bayesian point of view. And from a Bayesian perspective, we can interpret probabilities as beliefs in a variable, allowing us to put semantics onto the terms in Baye’s Rule as Posterior, Likelihood, Prior, and Evidence.
The maths
If I roll a dice a 1000 times, and every time it lands on a 1, any reasonable person would suspect that there is something wrong with the dice. After all, basic probability would tell us that each side should have a uniform probability distribution of 1/6; assuming that it is a fair dice. However, if I were to feed this information to a machine that only deals in absolute, i.e. can only understand frequencies of events, then it will guess that the next roll will also land on a 1 with 100% certainty.
If we were to design an AI that thinks like so, well then it’s not very intelligent. After all it cannot reflect on its choices and contemplate as it have no belief in anything. However, if we teach it some prior knowledge, a prior belief if you will, on the distribution of the likely outcomes, then it will then be able to reflect on whether or not the outcome would make sense.
To elaborate, let us use a simple linear regression model as our example. Regression is a good starting point as it is one of the common topic taught in A-level or high school statistics. From a frequentist approach, in a regression problem you would be asked to find the best fit line that describes the correlation between and (typically using OLS). But in machine learning, we often care more about learning how the patterns/correlations came to be. Specifically, we care about the parameters that define the structure of the function in the model, i.e. how exactly is mapped onto .
In a simple linear regression as above, the parameters are the weights and , where is the bias or offset parameter (y-axis intercept) whilst is the gradient parameter. These two parameters are what determine the exact structure of the best-fit line we have all come to know. Let us now define a joint distribution for our two parameters denoted as . However, when playing with probability there are many uncertainties that can arise, one of which is the uncertainty that the data itself can be corrupted. To take into consideration of errors/noise in the data, let us make an assumption that there is an additive noise in our model denoted as .
Where can assume that the noise is normally distributed with mean vector and variances . And by conjugacy, we can therefore also assume that the joint distribution for our parameters would be Gaussian too.
As previously stated, we need to first acquire a prior belief. In order to possess a prior distribution for our parameters, let us make another intial assumption that both parameters are independent. i.e. their joint distribution would entail a spherical covariance matrix, meaning there are zero covariances for all values of and . This would also entail an equal spread of uncertainty in both axes, which would also make sense since a prior belief is what you would belief initially before seeing any data, and if you haven’t seen any data then of course you would equally be uncertain of the values and . However, as you see more and more data you would then be able to see a pattern. Once you see how and correlates, the uncertainty in your prior distribution diminishes and equally you become more certain of the true value of both the parameters and that defines the true best-fit line of the data. This is better illustrated in the graphs below.


Take note as you observe more and more data, you start to learn the relation of the variables in the data better. And at every turn that you see more data, what you believed at the start (your prior) changes, and you then acquire a new update belief which we called your posterior. This whole process of updating your beliefs from prior to posterior and again and again is no different than how we humans learn. We all have some initial belief about something, and we either observe more information that confirms our beliefs or changes them. This is what it means to be learning. And this, is machine learning from a Bayesian perspective.
– to be completed –
Meanwhile check out my report on Bayesian modelling for more info on Bayesian approaches in machine learning, and also how we make inference after building our models.